
First, lets see what the stack looks like from a birds eye view
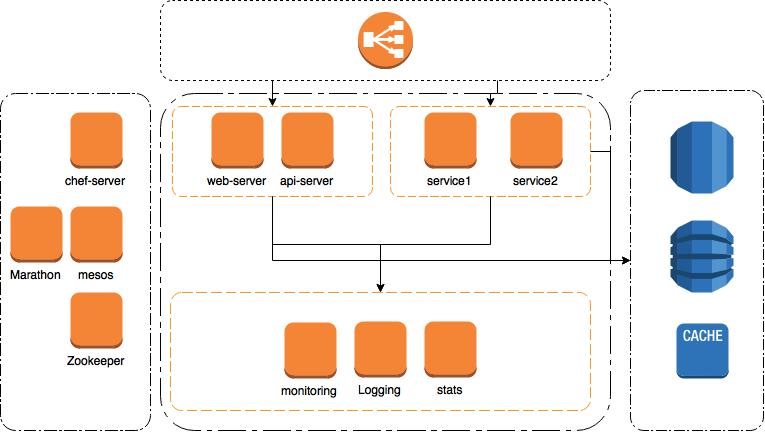
The stack is devided into multiple sections or logical segments
Configuration management and cluster management
Configuration
Configuration management is done with chef using chef-client and chef-server, this way each of the nodes, whether the node is just a docker host or a more traditional instance is managed by chef.
This management includes both state management and configuration management.
Lets take hosts management for example, chef is run on each of the nodes, updating the instance private ip in the hosts file for each of the node, this way, when Zookeeper is notified of the hostname, all of the servers already know the private ip for that hostname.
Cluster
Apache Mesos, Zookeeper and Marathon are all first class citizens in the stack.
Each of the nodes is a cluster member and runs the mesos agent. Potentially (although not being done right now), you can run docker or any other service on any of the nodes you have in your cloud.
We'll go deeper into these in the proper docs
Work instances
Work instances are servers or instances that actually get hit by user traffic, those are usually your web/api servers, backend servers, queue servers and others.
For example, lets say you have an API that is queueing up tasks to Sidekiq queue, those are part of the work instances group.
Watchers
Logs
By default, all Nginx Access logs are being sent to logstash, and there's configuration in place to send JSON logs.
All of the stack's services output logs in JSON format to work with logstash, this way, if you want to centralize logs from all the services, you can.
Stats
Graphite provides stats across the board.
There's nothing sending stats over there by default, but you can configure it pretty easily (details in the graphite cookbook of course).
Monitoring
Provided by Sensu, monitoring is on by default for all instances (if sensu is configured of course).
Default monitoring is for disk space, CPU, memory and of course there are defaults in place for monitoring services, cron jobs and more.
Data
No data persistence layers in the stack right now, it will be wise of you to use RDS or any other managed data provider at this point.
With data, there are a lot of things to consider like recovery, backups and more, it is beyond of the scope right now.